19. April 2026
Neue Objekt-Boundaries und verbessertes Snapping
Im Spatial Workspace unserer UI-Engine geht es stetig voran. Nachdem wir in den letzten Tagen die Performance bei tausenden Objekten gesichert haben, lag der Fokus heute auf einem entscheidenden Detail der räumlichen Interaktion: Wie exakt beanspruchen Objekte ihren Platz im Raum und wie verhalten sie sich, wenn sie aufeinandertreffen?
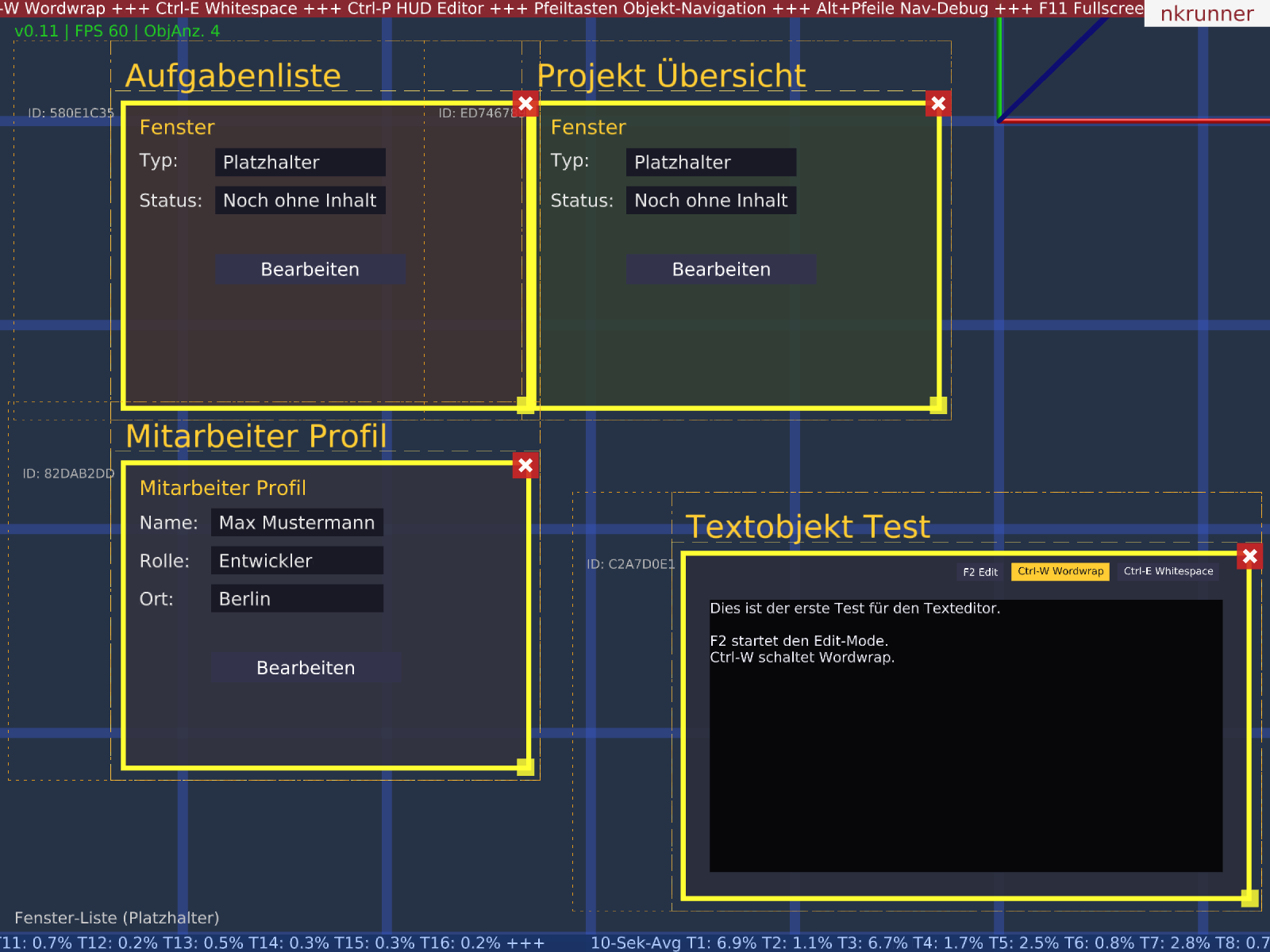 Abb 1: Die neuen Boundaries schließen das eigentliche Frame und die dazugehörige Caption in eine gemeinsame Bounding-Box ein.
Abb 1: Die neuen Boundaries schließen das eigentliche Frame und die dazugehörige Caption in eine gemeinsame Bounding-Box ein.
Das Problem mit den Beschriftungen
Bisher lag der Fokus der Kollisions- und Layout-Logik primär auf dem eigentlichen Fenster (dem Frame). Das führte in der Praxis allerdings zu visuellen und logischen Unsauberkeiten: Sobald ein Objekt eine Beschriftung (die Objcaption) besaß, die über das visuelle Haupt-Frame hinausragte, wurde dieser Platz vom System nicht vollständig respektiert. Beim Andocken von Fenstern konnte es passieren, dass Frames die Texte benachbarter Objekte überlagerten.
Erweiterte Objekt-Boundaries
Um das zu lösen, haben wir die Berechnung der Bounding-Boxen umgeschrieben. Die neuen Objekt-Boundaries umschließen nun konsequent das gesamte Element: Sie fassen das Haupt-Frame und die Objcaption zu einer gemeinsamen, logischen Einheit zusammen. Die Engine "weiß" nun exakt, wie viel Raum ein Objekt mitsamt seiner Metadaten und Titel wirklich benötigt.
Die neue Grundlage für das Snapping-System
Diese architektonische Anpassung ist weit mehr als nur ein optischer Fix. Die neuen Boundaries bilden ab sofort die exakte mathematische Grundlage für die Snappings zwischen den Frames.
Wenn Nutzer nun Virtual Windows im 3D-Raum verschieben und diese aneinander andocken, greift das Constraint-System auf die erweiterten Bounding-Boxen zurück. Das Andocken passiert exakt an den Außenkanten dieser neuen Geometrie – was zu einer völlig neuen, flüssigen Gruppendynamik führt.
Rasten beispielsweise die drei Masken-Frames aneinander ein, bilden sie fortan einen kohärenten Verbund. Zieht man nun an einem dieser Frames, gleiten die anderen beiden durch die magnetische Bindung nahtlos und synchron mit durch den Raum. Das angrenzende Texteditor-Frame hingegen ist von diesem System bewusst ausgenommen; es bleibt stets ein autarkes, frei platzierbares Element, das sich nicht in diesen Bewegungsfluss einklinkt.
Das Ergebnis ist ein extrem sauberes Layout-Verhalten ohne überlappende Texte. Das visuelle Element der Caption ist endgültig zu einem vollwertigen, berechenbaren Teil der räumlichen Geometrie geworden.